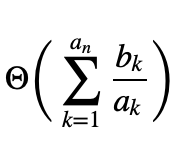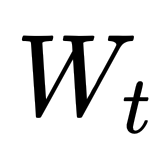Franklin's blog
You can find my CV here.
About me in English
Hi, I'm Franklin! I'm a software developer living in Albuquerque who likes programming, math and learning languages.
Sobre mí en español
¡Hola, soy Franklin! Soy un desarrollador de software que vive en Albuquerque y me gusta la programación, las mates y el aprendizaje de idiomas.
Über mich auf Deutsch
Hallo, ich bin Franklin! Ich bin ein Softwareentwickler und ich wohne in Albuquerque. Mir gefallen das Programmieren, die Mathematik und das Sprachenlernen.
Обо мне на русском
Привет, меня зовут Франклин! Я работаю программистом и живу в Альбукерке. Я люблю программирование, математик и изучение языка.
Here are some of my recent web projects:
Recent posts
View all posts
...and here are some things that aren't posts
 Untersuchung von einer schwingenden Beatty-artigen Folge
Untersuchung von einer schwingenden Beatty-artigen Folge