WebSockets para realizar computaciones remotas
(Psst! Don't want to read this in Spanish? Here's a translation.)
Lo corriente que es ejecutar código remoto
Lo que pretendo describir en esta entrada no es de ninguna manera una idea nueva ni una muy compleja, sino es una idea muy básica pero muy fácil de olvidar mientras andas visitando páginas web como usuario del internet. Cuando visitas una página web, tu navegador, que es una aplicación multiproceso de tu ordenador, abre una conexión con un servidor remoto, a través de la cual descarga el código HTML de la página. Si requiere recursos que no vienen incluidos en el código HTML, como por ejemplo imágenes, estilos CSS o código JavaScript, pueden producirse peticiones adicionales al servidor para solicitar estos recursos e incorporarlos en la representación de la página que te presenta el navegador. Los protocolos HTTP y HTTPS describen cómo funciona este proceso.
Por supuesto, el simple acto de descargar código de una fuente remota y no confiada presenta un peligro, pues si yo, el dueño del servidor remoto, pudiera ejecutar cualquier código que quiera en tu ordenador, entonces podría robarte todos los datos delicados que se encuentren en tu ordenador, instalar software que me permite espiar en tus actividades o aprovechar de tu procesador remotamente, etcétera. Pero si tus interacciones con el internet ocurren a través de la interfaz de tu navegador, y éste no posee defectos de seguridad, entonces se encargará de no permitir que la ejecución de código descargado toque el sistema de archivos de tu ordenador sin tu autorización explícita. Pero en el pasado sí se han producido casos de navegadores no seguros que han permitido el robo o la manipulación del filesystem local por entidades remotas, y esto se considera una vulnerabilidad del navegador.
Pero para el funcionamiento correcto de la mayoría de las páginas web, ha de ejecutarse el código JavaScript que descarga el navegador, y cualquiera ejecución de código implica el uso de la CPU de tu ordenador. Así que, al acceder a un sitio web con un navegador bien seguro, tu filesystem local quedará inaccesible a la entidad remota con la que estableces una conexión, pero es cierto que le estás invitando a usar tu CPU. Bueno, no le invitas al uso exclusivo de tu CPU: el sistema operativo de tu ordenador se encargará de repartir el uso de la CPU entre los varios procesos que se ejecutan en tu ordenador, entre ellos los procesos lanzados por tu navegador. Como cada proceso, tendrá que esperar su turno, pero con el trozo de tiempo de CPU que tu sistema operador se le asigna, puede hacer lo que quiera con respecto a computaciones, sin que se considere un problema de seguridad.
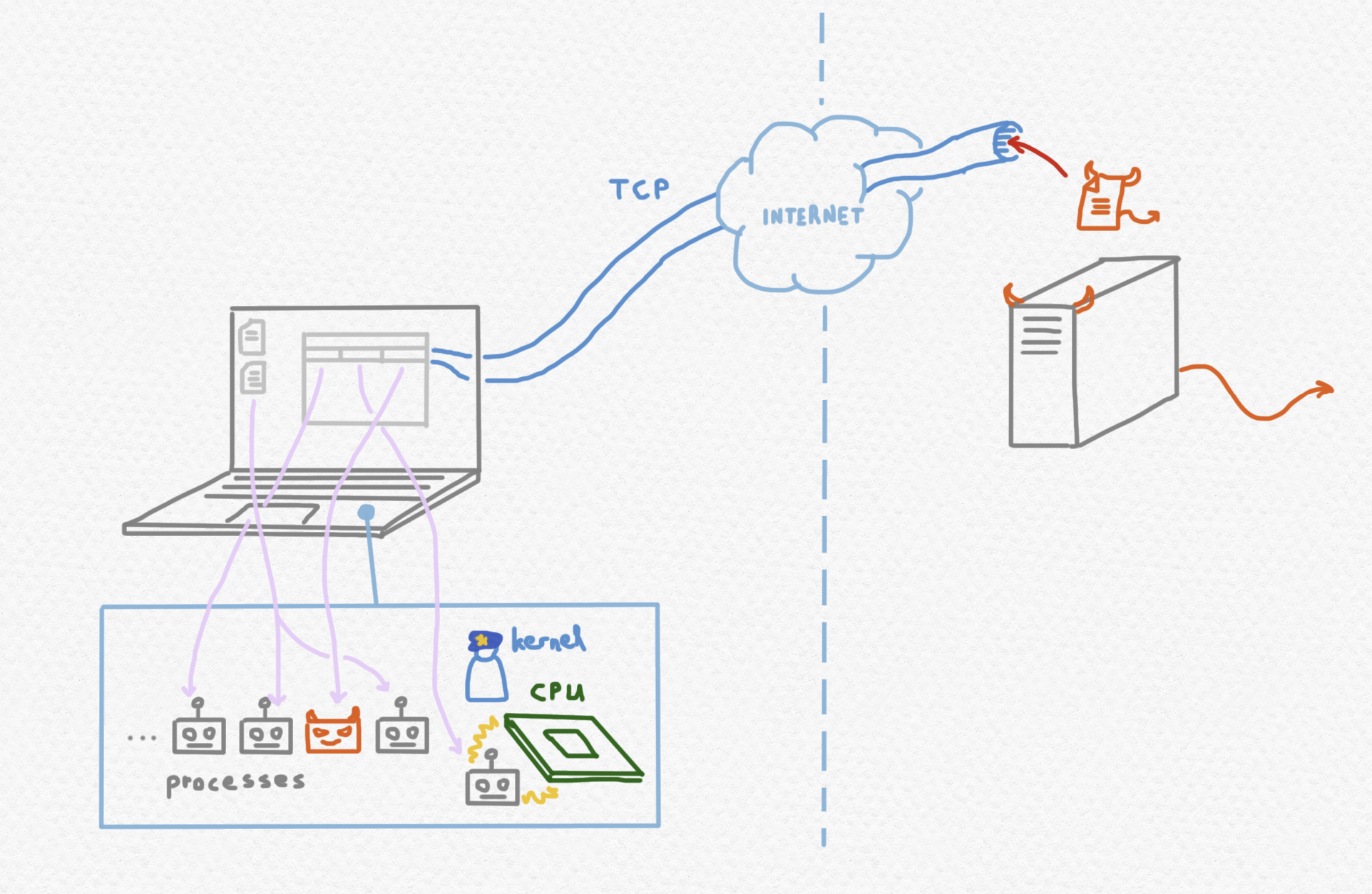
Algunas aplicaciones de web involucran comunicación continua entre el proceso local que se ejecuta en el cliente y el proceso servidor que se ejecuta remotamente. Esto también se considera legítimo por lo general. Imagínate por ejemplo que accedas a un videojuego a través del navegador, que involucra la descarga de varios recursos multimedia (audio, imágenes, etcétera) que a lo mejor ocurrirá dinámicamente por motivos de rendimiento (mejor no descargar todos los recursos involucrados en el videojuego de golpe, sino sólo los que se van a necesitar dentro de poco). Un tal intercambio continuo de datos se puede realizar a través de varias conexiones HTTP (o una sola conexión a partir de HTTP 1.1), o se puede realizar mediante WebSockets.
Así que, si yo ofrezco una página web en un servidor mío, probablemente puedo contar con un trozo considerable de la CPU de cualquier fulano que accede a ella, además de comunicación continua con el proceso mío que se está ejecutando en su ordenador. Pues esto es exactamente lo que hacen la mayoría de las páginas web, así que poco derecho de quejarse tiene este fulano si me aprovecho del trozo de CPU que me ha regalado. Y si elijo realizar minería de criptomonedas o lo que quiera yo para mi propio provecho además de lo que sea necesario para el funcionamiento de la página web, ¿cómo va a darse cuenta el cliente, a menos que se ponga a descifrar el JavaScript ofuscado que le he enviado? (Bueno, ya veremos como podría darse cuenta.)
A continuación, demuestro como un servidor web sencillo puede aprovechar de los trozos de CPU alocados para el trámite de su página web para resolver problemas computacionales en los ordenadores que acceden a ella. No asevero que lo que presento aquí sea práctica ni eficiente - sólo lo propongo como una demostración sencilla de lo que acabo de describir, y un recordatorio de lo que uno está permitiendo que un servidor remoto haga al acceder a su sitio web a través del navegador de manera que se considera totalmente segura.
Factorización remota de enteros
Aquí veremos como aprovechar de CPUs ajenas para factorizar números enteros. Pues, no tengo por qué querer factorizar números enteros - sólo quiero demostrar un ejemplo sencillo de una aplicación que obtiene los resultados de computaciones sin realizar computaciones por su propia cuenta salvo la emisión y recepción de datos por la red.
Usaremos el paquete Flask de Python para proporcionar una página web que realiza factorización de enteros en el fondo. Primero, crearemos un fichero HTML con el cuerpo siguiente:
Aquí está algo entretenidísimo que capta la atención del fulano...
En la cabeza de la página podemos meter código JavaScript, por ejemplo la siguiente rutina que factoriza números enteros:
function pfactors(n) {
var factors = [];
var d = 2;
while (n > 1) {
while (n % d == 0) {
factors.push(d);
n = n / d;
}
d++;
}
return factors;
}
Bueno, no es el algoritmo más eficiente, pero basta para una ilustración. En el servidor remoto, metemos un fichero HTML con estos contenidos en static/index.html, donde lo buscará nuestro servidor Python al recibir una petición. Ahora a escribir el servidor. Con el código siguiente podemos simplemente servir la página HTML que acabamos de escribir:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return app.send_static_file('index.html')
if __name__ == '__main__':
app.run(host="0.0.0.0")
Hasta ahora no hacemos nada excepto enviarle la página web al cliente. Si enciendo el servidor remoto de Python y entonces visito la dirección XX.XXX.XX.XXX:5000 en mi navegador (donde XX.XXX.XX.XXX representa la dirección IP de mi servidor, la cual elijo ocultar) me sale la página que acabamos de escribir. Y aunque todavía no realizamos ninguna computación remota, podemos comprobar que la función pfactors que escribimos esté disponible en el navegador del cliente. Si abro la consola del navegador, puedo realizar una factorización manualmente:
> pfactors(100)
< [2, 2, 5, 5]
Para realizar computaciones remotamente en el cliente, implementaremos un protocolo muy sencillo:
- Al cargarse la página web, el cliente establece una conexión con el servidor por un WebSocket.
- El servidor le envía al cliente un entero aleatorio que se desea factorizar.
- Al recibir un entero por la conexión, el cliente lo factorizará usando
pfactorsy devolverá el resultado al servidor a través de la misma conexión. - Al recibir una respuesta del cliente, el servidor le enviará otro entero aleatorio para factorizar.
- El servidor y el cliente siguen así hasta que se cierra la conexión.
Modificamos el código del servidor así:
from flask import Flask
from flask_sock import Sock
import random
def write_factors(n, res):
with open("factors.txt", "a") as datafile:
datafile.write(str(n) + " -> " + res + "\n")
app = Flask(__name__)
sock = Sock(app)
@app.route('/')
def index():
return app.send_static_file('index.html')
@sock.route('/factoring')
def factoring(ws):
while True:
n = random.randint(2, 10**10)
ws.send(str(n))
text = ws.receive()
write_factors(n, text)
print("A number has been factored.")
if __name__ == '__main__':
app.run(host="0.0.0.0")
y añadimos el código JavaScript siguiente a la página HTML que servimos:
var ws = new WebSocket("ws://XX.XXX.XX.XXX:5000/factoring")
ws.onmessage = function(evt) {
var received = evt.data;
ws.send(pfactors(Number(received)));
}
Entonces, si enciendo el servidor de nuevo, abro la página web en mi navegador por algunos segundos como si estuviera leyéndola, y entonces cierro la pestaña, se ve que han aparecido varias factorizaciones en el fichero factors.txt del servidor:
7328499434 -> 2,17,257,838693
3792814921 -> 7,41,13215383
4083310343 -> 7,37,15765677
4401689293 -> 643,757,9043
3979661166 -> 2,3,3,3,13,89,63697
6915352069 -> 6277,1101697
393300005 -> 5,7,11237143
5359459099 -> 19391,276389
2532264950 -> 2,5,5,50645299
3794691709 -> 1237,3067657
7519596251 -> 31,242567621
9625185328 -> 2,2,2,2,11,37,1478069
645966521 -> 41,167,94343
Se nota también que el proceso lanzado por la página web se encuentra entre los más caros en el ordenador. Por ejemplo, puedo utilizar el orden top en para comparar el uso de CPU de los procesos actualmente vivos en mi ordenador, y se ve que el valor de la estadística %CPU del proceso que le corresponde a esta página web vale alrededor de 99% en cada instante. Vale notar que un valor de 99% para la estadística %CPU no indica que la CPU de mi ordenador se dedica a ejecutar este proceso el $99\%$ del tiempo y los demás procesos un mero $1\%$ del tiempo, sino que este proceso utiliza el $99\%$ de la CPU que el kernel se le otorga. Si se interpreta esta estadística de la manera equivocada parece mucho más grave lo que está pasando que lo que realmente es. A lo mejor, este proceso no está recibiendo más tiempo dedicado de CPU que los demás procesos lanzados por tu navegador - pero del tiempo que recibe, utiliza un porcentaje mucho mayor como tiene muchas computaciones que realizar. De hecho, puede ser que reciba menos tiempo dedicado de CPU de los demás procesos, como muchos algoritmos de planificación perjudican a los procesos que utilizan un porcentaje mayor de su trozo de tiempo.
Consideraciones prácticas
Ahora, quiero poner una pregunta: ¿es factible realmente aprovechar de computaciones caras realizadas de manera distribuida y oculta a través de los navegadores de los visitantes a una página web? No es difícil de demostrar la posibilidad de realizar esto - acabamos de hacerlo. Pero lo que dudo es que se pueda implementar de manera provechosa, por varias razones:
- Aunque el servidor remoto ahorra CPU así, sigue comunicando continuamente por la red, que también le cuesta algo.
- El proceso lanzado para ejecutar el JavaScript de una página web probablemente no recibirá un trozo muy grande de CPU.
- Si el navegador detecta el código de una pestaña en particular esté usando muchísimo CPU, podría avisarle al usuario de la posibilidad de que sea maliciosa.
- El usuario puede cerrar la pestaña y terminar el proceso en cualquier instante.
Entonces, aún si fuera yo dueño de un sitio web de millones de visitantes (ojalá!), probablemente no podré contar con que una conexión concreta permanezca vivo por más que, digamos, un par de minutos a lo máximo (aunque depende de lo entretenido que es lo que le proporciono al cliente, jaja). Además, si se cierra la conexión antes de que se acabe la computación, entonces se perderá todo el progreso hecho hasta ese punto. En concreto, si se modifica el ejemplo anterior para que el servidor elija enteros aleatorios de $[2,10^{15}]$ en vez de $[2,10^{10}]$, se ve que sucede con frecuencia que no se logra factorizar ningún entero, o tal vez solo uno o dos, dentro de un interval de varios minutos. Así que, si se va a utilizar esta técnica para resolver algún problemas computacional, debe de ser un problema masivamente paralelizable que se puede descomponer en pedazitos cada uno de los cuales se puede resolver dentro de un par de minutos a lo máximo.
Se me ocurre una manera posible de recuperar de la posibilidad de perder la conexión en cualquier instante y con ella todo el trabajo ya realizado pero todavía no comunicado. Podría ser posible informarle al servidor periódicamente del estado de la computación antes de que se termine. Por ejemplo, la función pfactors que escribimos puede tardar mucho en devolver un valor si se la usa para factorizar enteros grandes, pero toda la información necesaria para conocer el progreso de la computación en cualquier instante está presente en los valores de los variables n, d, factors. Si el proceso se acaba en el cliente antes de rematar la factorización, pero le ha notificado ya al servidor que tenía un valor de d = 500000 y un array de factores todavía vacío, entonces no hace falta que el siguiente proceso que reanude la tarea de factorizar el mismo entero en otro cliente empiece de nuevo con d = 0, pues ya se sabe que no hay factores menores que 500000. Así que, como desafío, he modificado el código anterior para que los clientes le envían al servidor una actualización de su estado cada vez que d alcanza un múltiplo de 10000000. Aquí está el código modificado del servidor:
from flask import Flask
from flask_sock import Sock
import random
jobs = [[random.randint(2, 10**10)]*2 + [2] for i in range(100)]
def write_factors(n, res):
with open("factors.txt", "a") as datafile:
datafile.write(str(n) + " -> " + res + "\n")
app = Flask(__name__)
sock = Sock(app)
@app.route('/')
def index():
return app.send_static_file('index.html')
@sock.route('/factoring')
def factoring(ws):
global jobs
active = True;
print("Connection established.")
while active:
job = jobs.pop()
ws.send(str(job)[1:-1])
print(str(job)[1:-1])
while (job[1] != 1) and active:
try:
text = ws.receive()
print("Progress update: " + text)
job = [int(x) for x in text.split(",")]
except:
jobs = jobs + [job]
print("The job was abandoned in state " + str(job))
active = False
if active:
write_factors(job[0], str(job[3:]))
print("A number has been factored.")
if __name__ == '__main__':
app.run(host="0.0.0.0")
Se generan las tareas de factorización que se desea realizar en una lista al principio, que se utiliza como variable global entre las hebras que lanza el servidor para los distintos WebSockets. Se guarda una tarea parcialmente completada como una lista donde los primeros tres elementos representan el número que se desea factorizar, el número original partido por los factores ya encontrados, y el valor de d, y los demás elementos representan todos los factoras que ya se han encontrado. Así que, una tarea que ni se ha empezado se guarda como la lista [n,n,2]. Entonces, cuando el servidor recibe una actualización del cliente, detecta si ha terminado la tarea para asignarle otra en este caso, y si se detecta que la conexión se ha cerrado inesperadamente, se guarda el progreso recibido hasta ese punto metiendo la actualización más reciente en la cola de trabajos de nuevo. Aquí está el código modificado del cliente:
function pfactors2(state, ws) {
var n = state[0];
var m = state[1];
var d = state[2];
var factors = state.slice(3);
while (m > 1) {
while (m % d == 0) {
factors.push(d);
m = m / d;
}
if (d % 10000000 == 0) {
ws.send([n,m,d,factors]);
}
d++;
}
ws.send([n,m,d,factors]);
}
var ws = new WebSocket("ws://XX.XXX.XX.XXX:5000/factoring")
ws.onmessage = function(evt) {
var received = evt.data;
var state = received.split(",").map(Number);
pfactors2(state, ws);
};
En esta nueva versión de la función de factorización que se llama pfactors2, se pasa como argumento una referencia al WebSocket para que pueda seguir enviando actualizaciones de manera continua. Si lanzo de nuevo el servidor y accedo a la página web en el navegador de mi portátil, y entonces cierro la pestaña antes de que se termine la computación, observo que la siguiente vez que lo vuelvo a abrir en una pestaña nueva, se reanuda la factorización del mismo entero sin haber perdido todo el progreso realizado anteriormente.
Sigo teniendo dudas de que este modelo pueda ser provechoso en algún contexto, pero a lo menos me parece interesante. Creo que ya se ha hecho mucha investigación que trata de la paralelización de various problemas computacionales, pero otro rompecabezas sería diseñar algoritmos que pueden funcionar en paralelo y recuperarse de pérdidas frecuentes de procesadores. Termino esta entrada con un problema teórico de optimización que me parece relevante e interesante:
Suponga que estás ejecutando tareas tal y como hemos descrito en los ordenadores de personas que visitan a tu sitio web, y que el tiempo que un usuario tarda en cerrar la pestaña se puede describir como un variable aleatorio que se conforma a una distribución exponencial $\text{Exp}(\tau^{-1})$ con tiempo promedio $\tau$. El progreso parcial de las computaciones realizadas se pueden guardar enviándoselo al servidor, pero el cliente tiene que gastar $\delta$ segundos del tiempo computacional que tiene asignado cada vez que prepara y realiza una actualización. Si se considera perdido todo el progreso que no ha sido guardado cuando un usuario cierra la pestaña, y que la "cantidad de trabajo" realizado en el cliente crece linealmente con una cierta tasa $\sigma$ en cada instante que no esté preparándose para enviar una actualización, ¿con qué frecuencia se debe realizar actualizaciones para aprovechar al máximo de la computación que se realiza a costa de los clientes?

