The appearance of dead links on my website is a recurring problem for me. At best I wouldn't have any non-functioning links on my website, but it would be very time-consuming and inefficient to go around clicking on all of my website's links just to see which ones are broken. In any case, this kind of repetitive task is better done by a bot than by a human. To this end I've developed a little webcrawler to discover dead links for me automatically. I'll briefly describe this crawler and then summarize the results of its traversal of my blog.
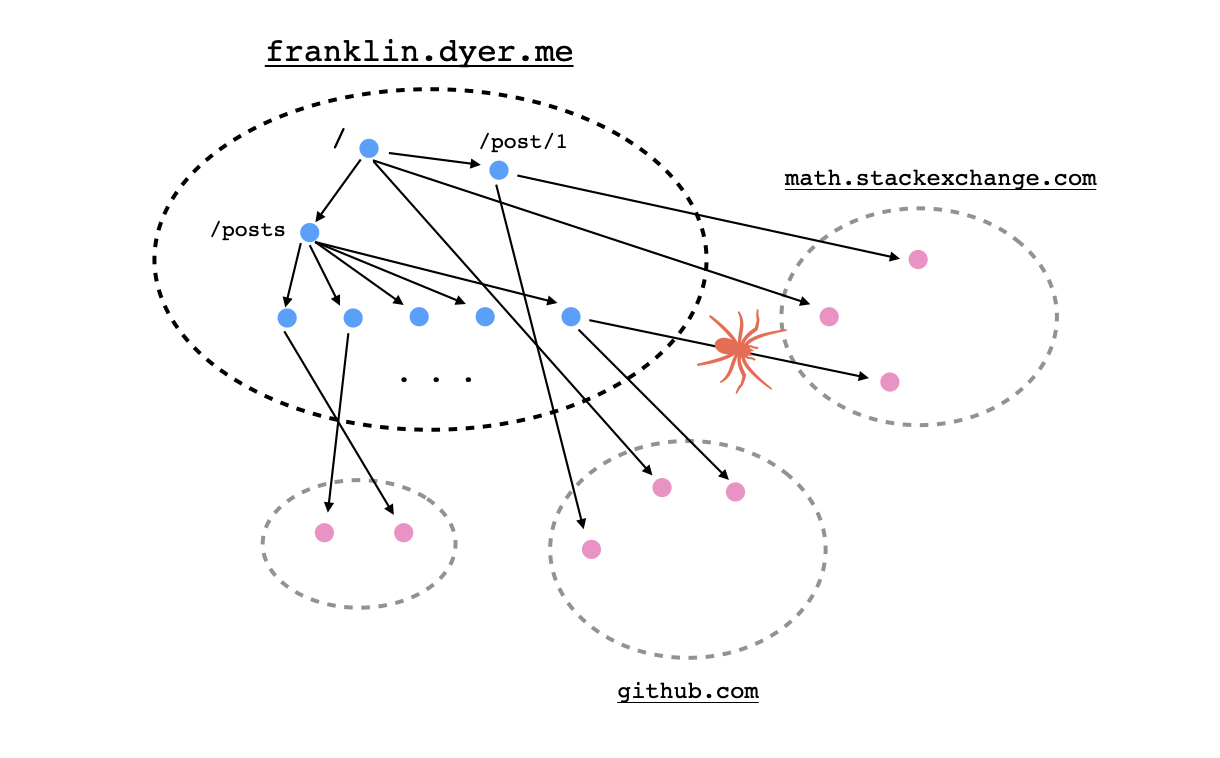
First, the bot takes as input from the user a starting link and identifies its domain name. From there, it will look through all websites with the same domain name that are reachable via a sequence of hyperlinks starting with the link provided. It carries out a breadth-first-search in which it inserts each link discovered on the current page into a queue and then continues on its search, visiting the next site in the queue. For sites with the same domain name, the bot inserts all found links into the queue, but for sites with different domain names, it merely checks that the linked resource exists without recursively inserting its links into the queue as well.
Here are a couple of small but important details regarding the implementation of this procedure. First of all, the webcrawler shouldn't waste any time following links that it has already followed, so it should maintain a list of links that have already been followed. However, it can be computationally costly to compare a link against many other links stored as strings, so my bot takes advantage of the implementation of associative arrays as hash-sets in Node.js.
Secondly, the bot shouldn't wait for a single HTTP request to be completed before making the next, but rather request several pages all at once. This way it can enjoy an efficiency benefit from concurrency, since it will spend less time idly waiting for the results of previous requests and instead use some of that time to process HTML that it's already received.
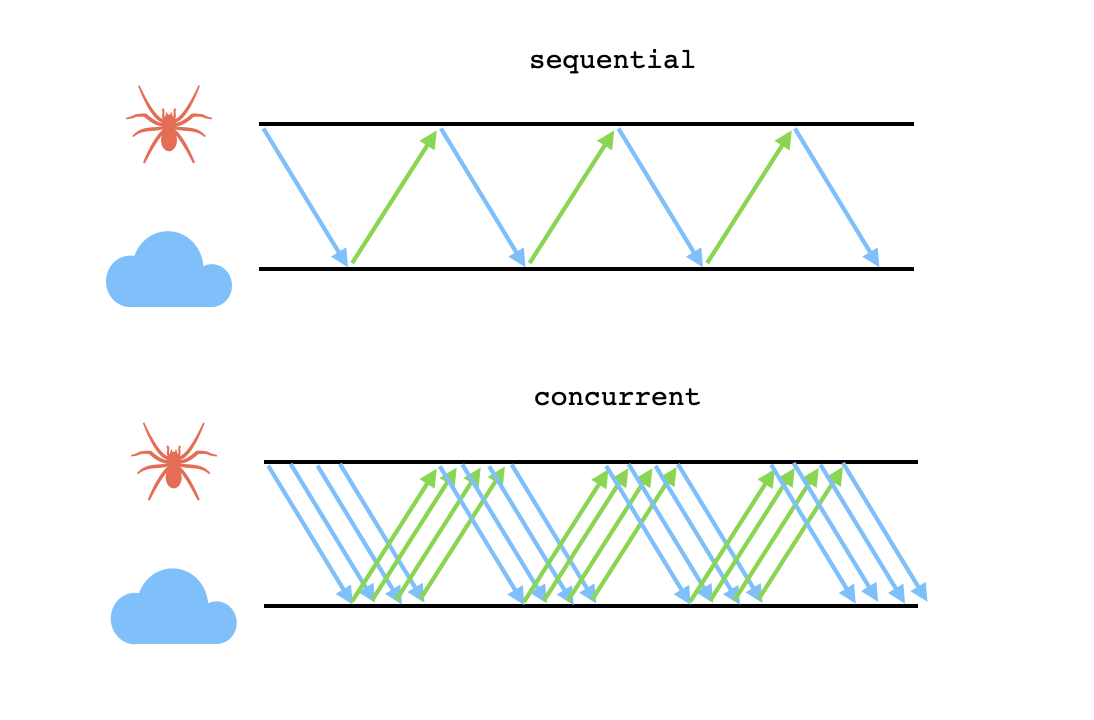
However, I've included a parameter in my code that places an upper limit on the maximum number of pending requests at one time. This can be used to avoid bombarding the website server with an exponentially growing number of requests.
Finally, it's worth clarifying what I meant when I said that it "checks that a linked resource exists". Each response to an HTTP request comes with a status code, with codes taking the form 4xx and 5xx indicating some kind of error condition, either on the client side or the server side respectively. For instance, the infamous 404 response code indicates that the client has requested a resource that doesn't exist, and this is a good indicator of a broken link.
Right now, my bot flags a link as being problematic whenever its request receives a response with any status code greater than or equal to 400. However, these are sometimes "false alarms" that are more indicative of peculiarities of the bot than actual broken links. For instance, while designing my bot and testing it on some websites other than my own blog, I discovered that several websites respond with 403 Forbidden to any HTTP request that has no user agent header, or that is using a disallowed user agent. This can sometimes be skirted just by submitting a spurious user agent header together with each HTTP request. Other websites implement rate limiting to throttle undesired bot traffic, returning 429 Too Many Requests if it receives a large number of requests in a short period of time from a certain client. In some cases, I've been able to avoid rate limiting penalties by decreasing the parameter that limits the number of pending requests at any given time.
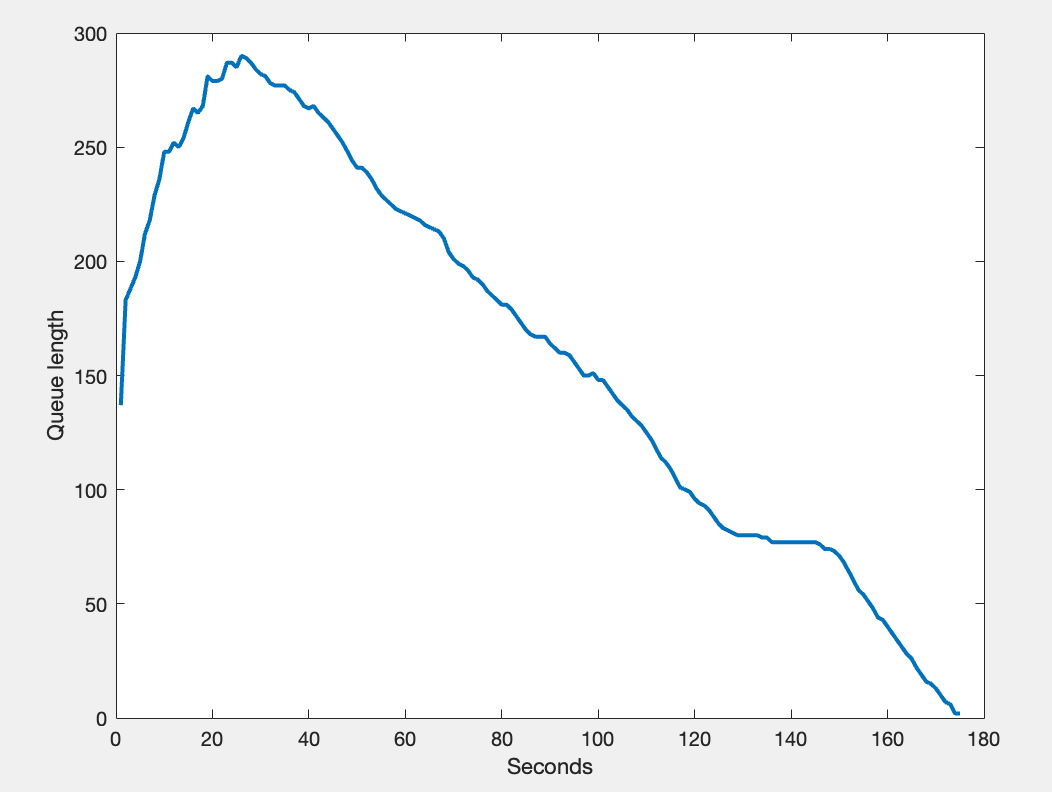
My personal website isn't very big, so the bot was able to carry out a complete traversal within just a few minutes. Below is a graph that shows the queue length as a function of the bot's runtime over the course of its complete scrape of my website, just to get an idea of how its backlog of links changes in size over the course of its execution:
I was able to discover a lot of broken links this way! If you want, you can read the results of this search here - in this document, I've included my personal assessment of each link that the bot has flagged, since it sometimes raises false alarms. It found a lot of dead links in my old math posts, many of which were accompanied by comments like the following:
Yikes! If someone was reading any of my older esoteric math posts (not likely...) then these dead links could have been really frustrating.

