A little encoding anomaly
A few days ago I visited the bookstore Barnes & Noble with my girlfriend and we bought three books. I noticed a strange detail in the receipt that they gave us after the purchase: Can you spot it?

The first books is called La hipótesis del amor but it was printed La hip≤tesis del amor on the receipt. If you're interested in a little googling puzzle, try and figure out what the cause of this little error could be. I've got my own tentative explanation, and I'll lay it out here.
The first possibility that occurred to me is that it could have something to do with the way the text was encoded. On a computer, the glyphs, or the geometric shapes that are considered individual symbols like the letters of the latin alphabet a,b,c,...,A,B,C,... or the arabic numerals 0,1,2,..., are encoded as strings of bit, like just about everything else stored digitally. To convert a digital document into something readable by either displaying glyphs in sequence on the screen or printing them on (say) a receipt, the strings of bits constituting a file need to be converted into a sequence of geometric shapes.
But there are different standards determining how bits are converted into characters. If the program that generates a text file uses one rule to convert between bits and characters while the printer uses another, the printed text could end up being different than the text shown on the screen. My theory, then, is that the program that was used to generate the digital representation of the receipt used a different code page than the receipt printer. The two code pages would have to be identical when it comes to the most commonly-used characters, such as the characters belonging to the latin alphabet, and differ in how they translate lesser-seen characters. In particular, the bit sequence representing ó according to the code page used by the process that generated the file would have to represent the character ≤ in the code page used by the printer.
The next step was to go looking for a pair of similar code pages that might have produced this error. One useful reference is the book Fonts and Encodings by Yannis Haralambous, that tells about the history of various different code pages in detail. One of the most well-known codes is ASCII. Originally, it represented each character with a sequence of $7$ bits, which could alternatively be represented as pairs of hexadecimal digits with the first being restricted to the range 0-7. Here's a table from Haralambous' book showing the 1967 version of the ASCII code page:
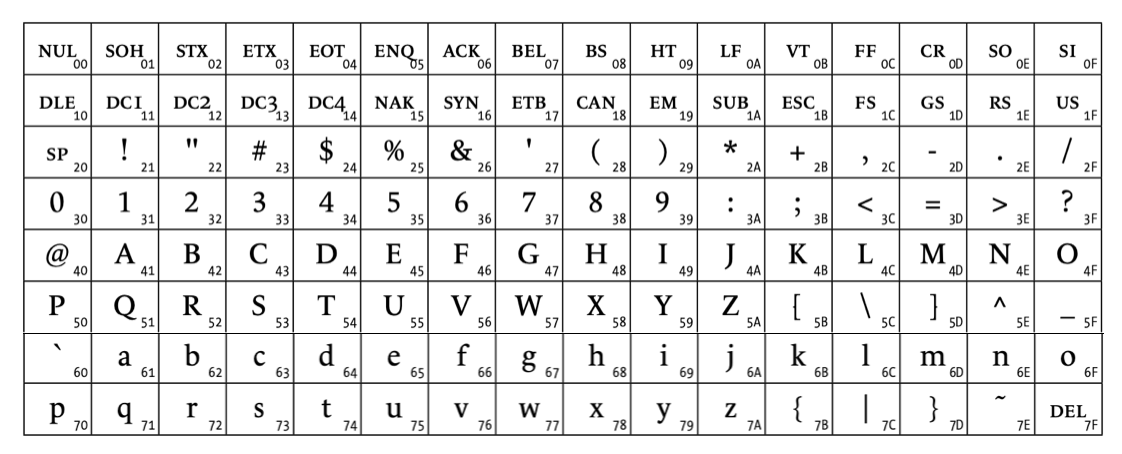
You can see that ASCII-1967 is pretty limited: it doesn't include the character ó at all, nor the character ≤. (Actually, there is a way of representing accents in ASCII-1967, but it's pretty clunky. The symbol ó could be represented as 0x6F0827, in which the backspace character is used to superimpose an o with an apostrophe. You could similarly represent ≤ as 0x3C085F.)
But many of the more commonly-used code pages nowadays are extended versions of ASCII consisting of $8$ bits per character, such that the codes between 0x00 and 0x7F are the same as those used by ASCII, while the codes between 0x80 and 0xFF are particular to the specific extension being used. As a starting point for my search, I looked for the specifications of certain receipt printers, although I didn't know what type was being used in the bookstore. For instance, the manual for this printer has a list of character sets on page 14, of which the most relevant ones seemed to be:
Code Page 437 US EnglishCode Page 850 MultilingualCode Page 1252 Windows Latin 1
By looking at the tables for these code pages, I noticed that code pages 437 and 1252 satisfy the necessary requirements. That is, they're both based on ASCII, but the code 0xF3 represents the character ≤ in code page 437 and represents the character ó in code page 1252. So, my conjecture is that the process that generated the receipt was using code page 1252 (this would make sense, since Windows computers are often used in businesses) and the printer was using code page 437, probably due to a default configuration. Here are the chunks of the two code pages that aren't inherited from ASCII:
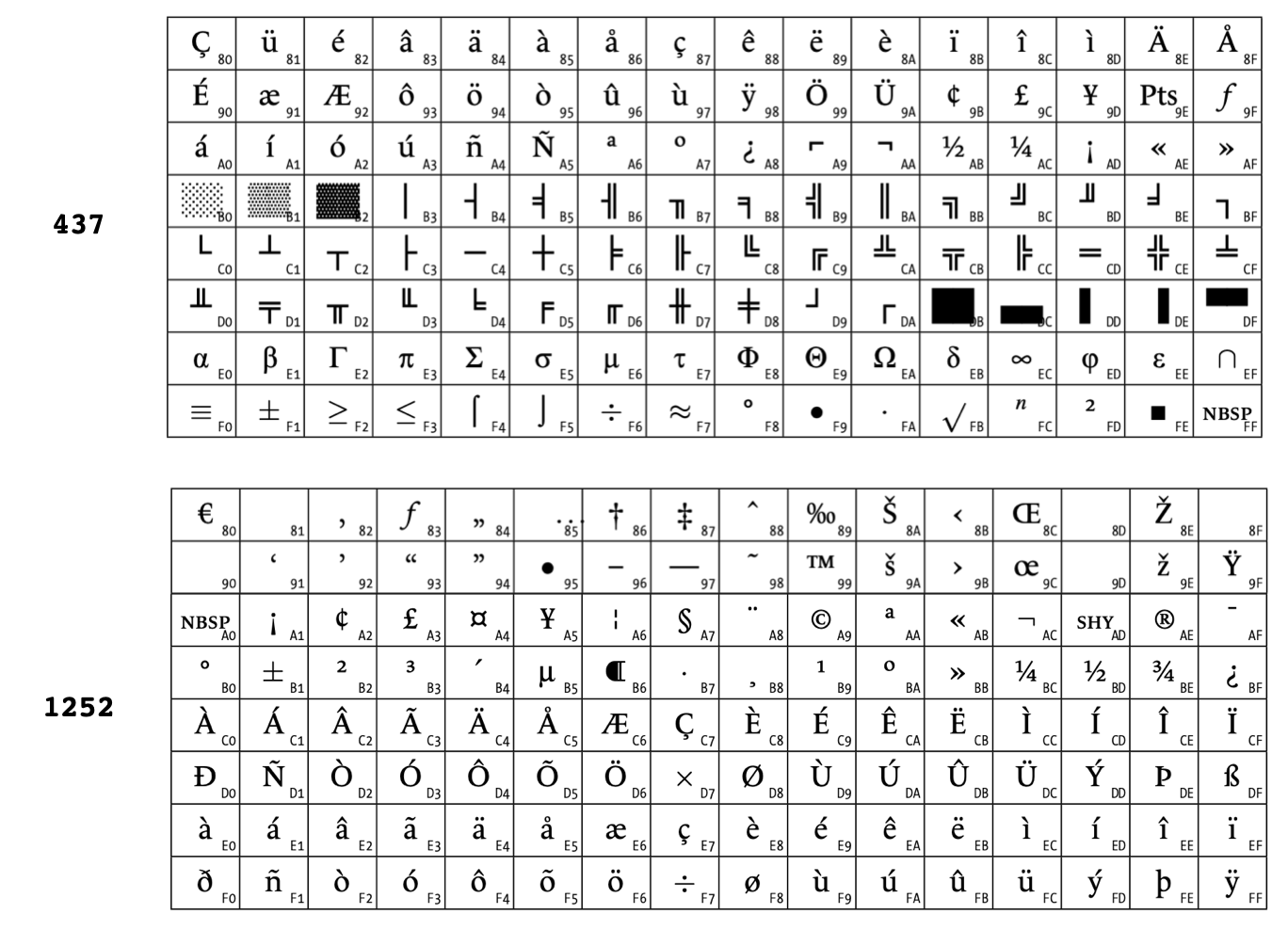
If correct, my hypothesis could predict other incorrect substitutions aside from the substitution of ≤ for ó, for instance a ± in the place of ñ or a µ in the place of æ. Well, if I go back to that Barnes & Noble, I'll make sure to buy the book with the largest possible number of characters falling outside of ASCII-1967, to see if my predictions are confirmed.

