For the past several months I've been a little bit obsessed with understanding how exactly character input works on my computer. When I press a key on my keyboard, where does that data go? Which processes on my OS see the value of my keypress? What are the different software representations of a keypress?
I've finally reached the point where I'm comfortable enough with this topic to write about it. Because my personal computer is a Macbook and I spend a lot of time coding from the command line, the OS- and application-specific details are centered on MacOS (currently Sonoma 14.2) and the Terminal application, but many of the tidbits here are broadly applicable. Figuring out how this compares to Windows and Linux in-depth would be a fun digression but I've chosen not to go down that rabbit hole here - maybe in another post! Regardless, much of what I've written here is somewhat applicable to Linux (especially the TTY stuff).
I feel that one could seriously write a novel on this topic, so I've tried to at least keep this blog post from appearing intimidatingly bloated by hiding some of the details behind accordion dropdowns. My understanding of some parts is woefully incomplete, so I may return to this post with edits as I keep digging.
Here's a diagram I made summarizing all of the steps in this journey:
Here we go!
(Keypress to scancode.) Physical keyboards typically don't know anything about character codes (ASCII, Unicode, whatever). Instead, they map keys to numbers called scan codes that are based on the row and column of each key on the physical keyboard. This includes both the keys corresponding to characters and the modifier keys like Shift, Control, etc.
There are several different possible physical keyboard layouts that determine how keypresses are mapped to scancodes.
Tell me more about how a Macbook uses its built-in keyboard or an external USB keyboard
A keyboard (or any kind of peripheral) must use some kind of bus to communicate with a computer. There are several existing standards for bus communication, among which are the USB standards.
On MacOS, you can view information about hardware peripherals by opening
System Preferences > General > System Information. In this menu, I was able to see metadata about a USB keyboard that I had connected to my Macbook. I was also able to find out that the built-in keyboard and trackpad use a different standard called Serial Peripheral Interface.We have to make a distinction here between a device controller and a device driver for computer peripherals. The former is a piece of hardware, and the latter is a piece of software. The device controller and driver depend on the bus protocol used by the peripheral, whether it be USB or SPI or something else (e.g. the legacy standard PS/2), and decodes electronic signals from the peripheral into bytes. The device driver makes these bytes available to the OS by providing a software interface for interpreting and retrieving them.
USB keyboards are typically "passive" in the sense that they do not have their own power source, relying on the controller to generate a current for communication (and a clock signal for synchonization). Individual bits are transmitted using differential voltage across wires joining the keyboard and keyboard controller. You can actually see the exact current requirements of a USB keyboard from
System Information.The exact mechanics of this software interface on MacOS are still unclear to me. As far as I can tell from reading the
IOKitdocs: the hardware controller polls the keyboard for keypress information and generates interrupts through the hardware driver when there is keypress data to report. If I'm wrong and someone who knows better reads this - please correct me!
Tell me about some different keyboard layouts and how MacOS distinguishes them
Three of the most popular physical keyboard layouts are the ANSI layout (common in the US), the ISO layout (common in Europe) and the JIS layout (common in Japan). They are similar but not identical. Here's a picture of these three physical layouts (plus a few more) courtesy of Wikipedia:
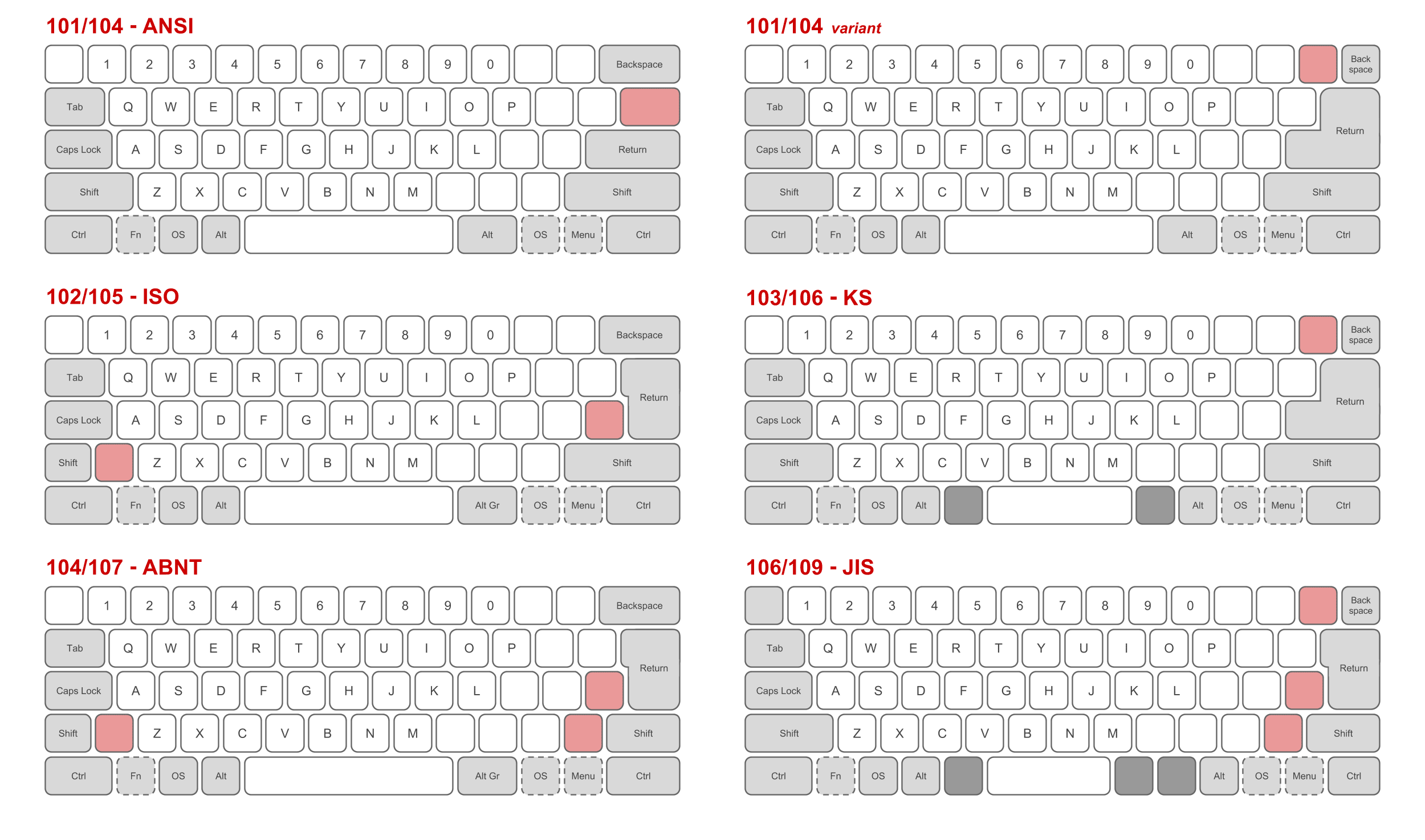
If you've used an external keyboard with your Macbook before, you may have seen a dialog box like this:
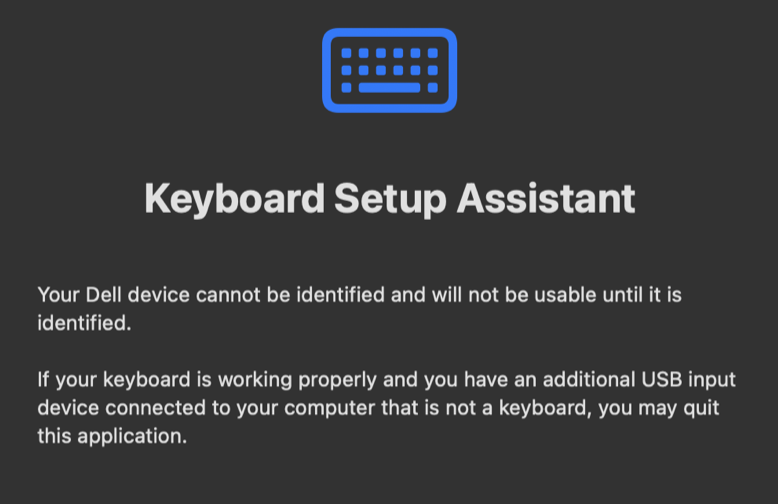
To identify the layout of your external keyboard, it asks you to press the key immediately to the right of your left-shift key, and then press the key immediately to the left of your right-shift key:
If you take another look at the keyboard layout diagram, you'll notice that the ISO layout has an extra key that the ANSI layout doesn't, just to the right of the left-shift key. (Its scan code is
0x56.) The JIS layout, on the other hand, has an extra key that neither ANSI nor ISO has, just to the left of the right-shift key. (Its scan code is0x73.)Hence, the OS can discriminate between a non-ISO and an ISO keyboard depending on whether the scancode from the key to the right of left-shift is
0x2c(the Z key) or0x56respectively; and it can discriminate between a non-JIS and a JIS keyboard ddepending on whether the scancode from the key to the left of right-shift is0x35(usually the?key) or0x56respectively. This means these two keypresses are enough to determine your keyboard layout, at least if you assume these three are the only options, as my Macbook seems to do:

(Scancode to HID message.) Keyboard scancodes are sent to the computer via an I/O bus. Scancodes aren't the only thing included in these messages: keyboards generally communicate with the operating system using the low-level HID (Human Interface Device) protocol, which is the same protocol used for mice and other low-bandwidth computer peripherals. This protocol can be contrasted with the other protocols that exist for storage or audio/video devices, which generally require much quicker transfers of data in bulk. A keyboard controller receives the HID messages and generates a hardware interrupt so that the OS can process the message. Thus transcends your humble keypress the confines of a hardware keyboard, entering the wonderful world of software.
Tell me more about the HID protocol
If you have a USB keyboard handy and Wireshark installed, you can actually inspect the HID packets yourself. According to the Wireshark Wiki, you can perform packet captures on the USB interfaces of recent Macbooks (for me, these interfaces were called
XHC0andXHC1). Unfortunately this requires disabling System Integrity Protection, so needless to say, I did not do any USB capturing on my main laptop. There's another app called USBPcap that purportedly allows you to accomplish something similar on Windows.I captured myself plugging in my USB keyboard to a Macbook laptop and typing the text "hello world". You can download my PCAP file here if you want to open it up for yourself in Wireshark. Here are a couple of interesting things I noticed:
Dell USB Entry Keyboard. Presumably this initial exchange is how my laptop discovered that it was a keyboard and not, say, a mouse or a thumb drive.English (United States). I'm unsure whether the self-reported language of the keyboard has any effect on how my laptop uses its input.
(HID message to kernel data.) Via the HID protocol, the OS has already identified your keyboard as a keyboard (and not a mouse, or a USB drive, etc) - so when it receives HID messages for keypress events, it knows to interpret them as keypresses. But keypresses are still described in HID messages as scancodes rather than character data. So the OS must translate each scancode by either producing a piece of character data (for data keys) or updating its internal representation of the modifier flags (for modifier keys).
Tell me about Karabiner
Karabiner is a really cool open-source app for MacOS for customizing the behavior of your keystrokes. It lets users customize the behavior of their keyboard in ways that are not possible with a keyboard layout (see next section). For instance, I discovered Karabiner while looking for a way to create a keyboard shortcut to type two parentheses and then position the cursor between the two parentheses. (I often find myself typing open- and close-parens immediately followed by the left-arrow key to enter text between the parens. Some IDEs do this for you automatically, but I wanted to do this with a single keystroke in a plain text editor.)
Karabiner captures keyboard events at what is arguably the lowest possible level in userspace software: by using the
IOHIDQueueclass exposed by the MacOSIOKit. It registers a virtual keyboard with the OS and produces its own sequence of virtual keypress events, as if they were coming from an entirely different physical keyboard. The development notes for Karabiner are quite insightful and discuss a few interesting edge cases.
(Kernel data to userspace data.) Having transformed keypress data from the keyboard into a more software-friendly form, the OS now decides what to do with it. On desktop systems, the event is usually transmitted to whichever application is "in the foreground". This is not the case for all keypress events, though. Consider the example of Cmd+Tab on MacOS. When this shortcut is enabled, it allows the user to cycle between running applications and quickly switch to a different foreground app, regardless of which app is currently in focus. (This is not to say that applications can't intercept Cmd+Tab at all - they can, but they won't receive the event by default.)
Tell me more about keypress events on MacOS
MacOS Core Graphics uses the
CGEventclass for representing low-level hardware events from peripherals, including both keypresses and mouse movements. It exposes an API for receiving and even manipulating keyboard input through something called an "event tap".Here's a simple Python script I wrote using the PyObjC library that prints some information about each keypress on my Macbook, including the scan code, a Unicode string, the modifier flags, the ID of the originating keyboard, whether or not the event resulted from a key being held down, and the PID of the process receiving the keypress event. Note that this works even when the Terminal running the Python script is not in focus.
Not all apps on MacOS need such low-level access to keypress information. MacOS also exposes the
NSEvent Classfor developers using its AppKit, which is more appropriate for applications that are not deliberately doing anything fancy with the keyboard.
Tell me more about keyboard layouts in MacOS
If you read the previous drop-down, you'll know that the keypress events that MacOS delivers to applications include a Unicode string. The Unicode string accompanying a keypress event does not have to correspond to the glyph printed on your keyboard in that position. The string included in each keypress event is determined by your keyboard layout.
You can configure your keyboard layout in MacOS (at the time of writing) by navigating to
System Preferences > Keyboard > Text Input > Input Sources. There are a number of preexisting keyboard layouts for world languages that you can select and add to your own "shortlist" of layouts that can be cycled through quickly. The OS is in charge of remembering which layout you have selected at any given time, and using it to decide what Unicode string add to each keypress event that it dispatches.Because this is handled at the OS level, customizing key mappings isn't a total free-for-all. However, there is an API for writing your own keyboard layouts in the form of XML files. Ukelele is a handy piece of software that provides a user-friendly interface for designing your own keyboard layouts, but it's not too difficult to edit the XML by hand. MacOS requires a computer restart to make user-written keyboard layouts available, so presumably they are loaded up when the system starts.
Tell me how
Cmd+c (copy to clipboard) and Cmd+v (paste from clipboard) are handled
There is nothing special about how
Cmd+candCmd+vare handled at the level of the operating system, as far as I can tell. These key combos are hotkeys like any others, and it is up to each application whether to interpret them as "copy" and "paste" or as something else. They're just ubiquitous enough that most apps choose to use them in this way when possible.On MacOS, the clipboard is simply a service that apps have access to through a specific API. Apparently AppKit exposes a class called
NSPasteboardthat any app can use to interact with a "pasteboard server" supporting certain actions that are enumerated in theNSPasteboardAPI docs. Clipboard contents can be more general than plain text data, and may include anything implementing theNSPasteboardWritinginterface.
(Userspace data to... something?) This is where it becomes impossible to give a general treatment of keyboard input, since different userspace applications can basically handle keypress events however they want. A text editor app may convert your characters into their ASCII or Unicode equivalents in its internal representation of a text file. A browser application usually captures some special hotkey combos and converts them into browser actions (e.g. Cmd+T for a new tab), but it delegates handling for most keypresses to individual websites by converting the keypresses into keyUp or keyDown events in Javascript. A text field may handle an a keyDown event into the character 'a', while a web-based platformer game using WASD controls may handle it by moving a player to the left.
Here we will specialize our treatment to a specific kind of application: terminal emulators, e.g. the Terminal app on MacOS.
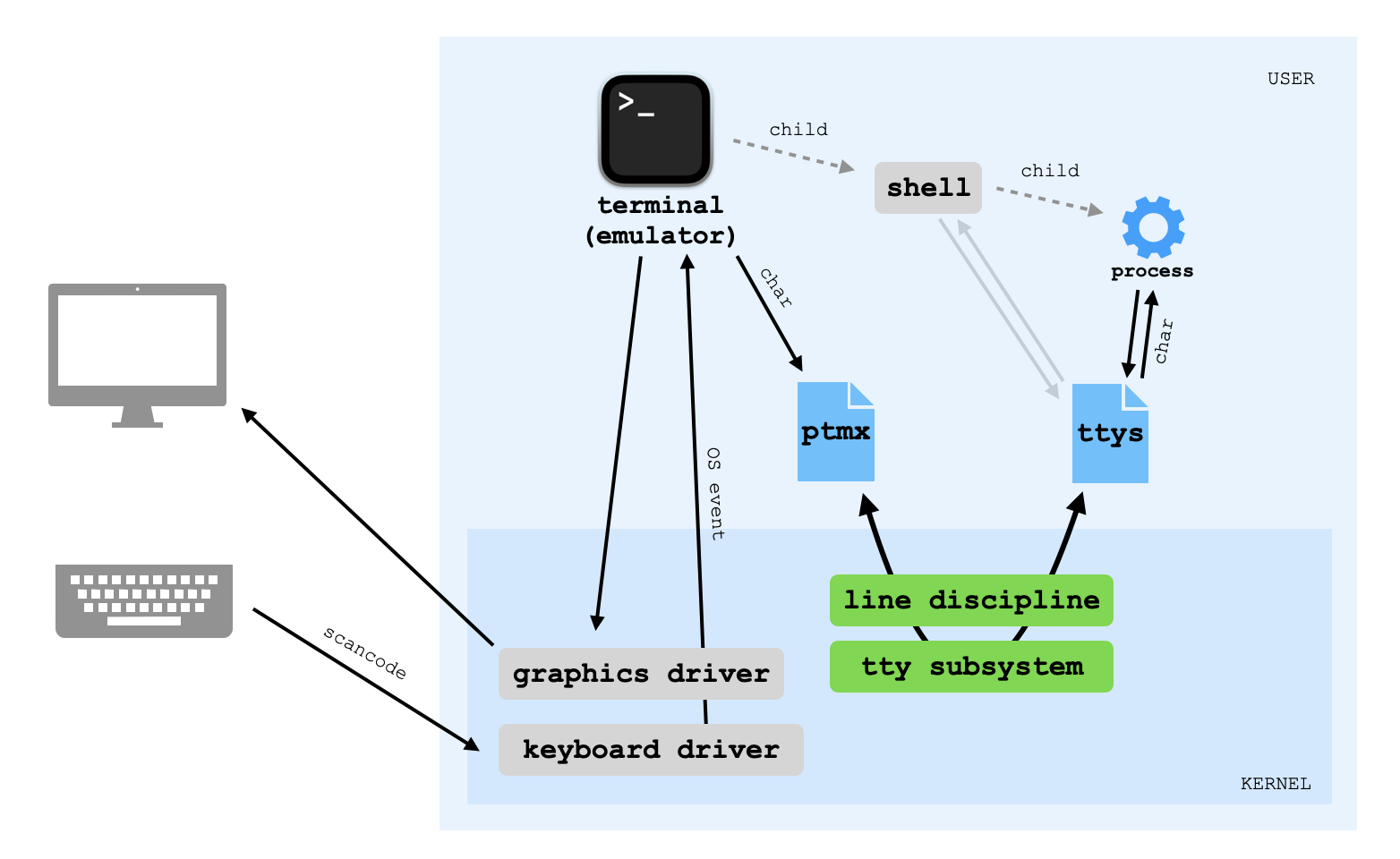
(Userspace data to PTY master.) Terminal emulators use something called the TTY system to communicate with shells. This system is a bit of a relic, having originated with a specific kind of hardware in mind (i.e. a teletypewriter paired with a video terminal) that has long since been replaced by a software abstraction.
First a bit of terminology:
Terminal or xterm)bash or zsh)If that wasn't very clear, I recommend taking a look at The TTY Demystified, which explains the historical origins of TTY and PTY devices.
Before describing how a single character passes through the PTY system, let's briefly discuss what the terminal emulator needs to have done beforehand. Each "mock terminal session" is associated with a pseudoterminal master and pseudoterminal slave device, corresponding symbolically to the two ends of a physical wire that would join a teletypewriter to a computer (back when dinosaurs roamed the Earth). These devices are created by reading from /dev/ptmx, the terminal multiplexor device. The sequence of events looks something like this:
Terminal) opens/dev/ptmx and gets a master file descriptor fdmfds by calling ptsname on fdmfork, spawning a child processfds and points stdin, stdout and stderr to fdszsh)This all needs to happen before we start typing things into the terminal emulator. Then, when it receives a keypress event from the OS, unless it's a hotkey specific to the terminal emulator, it just writes the character data to its master PTY file descriptor.
Tell me how to use
/dev/ptmx by hand
Have a look at this small C program, which does nothing more than create a new TTY slave by opening
/dev/ptmx, writing to it in a parent process and reading from it in a child process.
Tell me how special characters are sent
The shell
/bin/zshhandles several special keystrokes that aren't interpreted as character data, such as the arrow keys, which are used to inspect the command history or move your cursor around within the command you're typing. But this must means that the arrow keys are somehow written to/dev/ptmxand read from some slave device/dev/ttysXXX, even though the arrow keys do not naturally correspond to any character. How does this work?You can actually figure this out for yourself with a bit of trickery. By reading directly from the TTY slave device currently in use by a shell, we can intercept the bytes that the terminal emulator is sending our shell and dump them into a file, where we can inspect them. Try following these steps:
Terminal window.tty. This prints the name of the TTY slave device in use by the shell.Terminal window.cat /dev/ttysXXX > dump.txt, where /dev/ttysXXX is the name you found in part 2.Ctrl+c.dump.txt with a hex editor.Your file probably looks something like this:
00000000: 1b5b 415b 415b 411b 5b41 5b41 5b41 5b41 .[A[A[A.[A[A[A[A
00000010: 5b41 1b5b 411b 5b41 5b41 5b41 1b5b 415b [A.[A.[A[A[A.[A[
00000020: 415b 415b 415b 431b 5b43 5b43 431b 5b43 A[A[A[C.[C[CC.[C
00000030: 5b43 5b43 1b5b 435b 435b 431b 5b43 5b43 [C[C.[C[C[C.[C[C
00000040: 5b42 1b5b 425b 425b 421b 5b42 5b42 5b42 [B.[B[B[B.[B[B[B
00000050: 1b5b 425b 425b 421b 5b42 5b42 5b42 1b5b .[B[B[B.[B[B[B.[
00000060: 445b 445b 441b 5b44 5b44 5b44 5b44 5b44 D[D[D.[D[D[D[D[D
00000070: 1b5b 445b 445b 445b 445b 445b 445b 44 .[D[D[D[D[D[D[D
What you're seeing are the ANSI escape codes. These codes comprise a protocol that were once used by video terminals to communicate with processes, and are now used by terminal emulators like
Terminal. ANSI escape codes are used for terminals to send special commands to shells that are not meant to be interpreted as character data, as well as a way for shells or other processes to send commands back to the terminal telling it how to alter its appearance. The escape codes for the up, right, down and left arrow keys respectively are0x1b5b41,0x1b5b43,0x1b5b42and0x1b5b44.You might notice that in the above hex dump, these byte sequences are not always complete. For the up arrow, sometimes we see the full
0x1b5b41, and sometimes we just see a0x5b41. This is because of a race condition: the shell andcatprocesses were performing concurrent reads of/dev/ttysXXX, and the escape sequences are multiple bytes long, meaning that there is a chance that the different bytes comprising a single escape sequence will be read by different processes.
Tell me how
Ctrl+c is handled
You may be familiar with
Ctrl-cas the key combination to press if you want to kill a process running in your terminal. How exactly does this work?When you press this key combination, the terminal emulator writes
Ctrl-cto the TTY master as usual. However, the way this data is handled at the kernel level is different. Rather than making this data readable as bytes from the slave TTY, the TTY subsystem takes this as an indication that it should send aSIGINTsignal to the foreground process in the shell's process group.The default behavior for handling the
SIGINTsignal is to exit. This is why, if you pressCtrl+cwhile a program you've launched from the terminal is running, it will usually exit. However, the way this signal is handled is actually up to each process. You can write a simple program in C with a customSIGINThandler that does nothing when it receives this signal, and therefore does not respond toCtrl+C.You can also use
sttyto change this behavior in the kernel, so thatCtrl+Cis carried to the slave TTY as data and another key is translated into an interrupt signal. For instance, runningstty intr kwill givekthis special role. This is just one of the many TTY configuration options that the operating system API offers (a couple more are discussed in the next section).Julia Evans has had some fun categorizing all of the different terminal control characters like
Ctrl+C- check out her post!
Tell me how
ssh (the Secure SHell) fits into this picture
For simplicity's sake, I'm only talking here about the command-line application
ssh. SSH also is the name of a more general protocol that can be used with different frontend clients, e.g. PuTTY for Windows.First of all,
sshis a bit of a misnomer. It is not a shell at all, because it is not the parent process that spawns child processes based on the commands you type in. SSH is more like a relay that uses network connectivity to connect a terminal emulator on one host with a shell running on a completely different host.OSs commonly come with an SSH daemon such as
sshdinstalled, which is usually configured to listen persistently to port22(by default). When you initiate a connection, your client machine makes a series of requests to port22of the remote host, where the daemon must be listening to receive it. Assuming this is successful, the daemon authenticates you using a public-private key pair or password.After this, you can use the shell on the remote machine in a more or less seamless way, as if you had a terminal directly plugged into the remote machine. This illusion works so well because the terminal emulator is local while the shell is remote. As for how this fits into the TTY system: the SSH client on your local host reads from the local TTY slave device, and the SSH daemon on the remote hots spins up its own master-slave TTY device pair while processing your request, with the daemon using the master end and the shell using the slave end. Each character you type undergoes the following journey:
/dev/ptmx file descriptorssh (client) reads the character from its TTY slave filessh (client) creates an encrypted payload containing the character using the server's pubkeyssh (client) sends the payload using the TCP protocol, which generally requires four segmentssshd (server) receives the payload and decrypts it using its private keysshd (server) writes the character to its /dev/ptmx file descriptorHere's a revised version of my original diagram that depicts the situation when you use SSH:
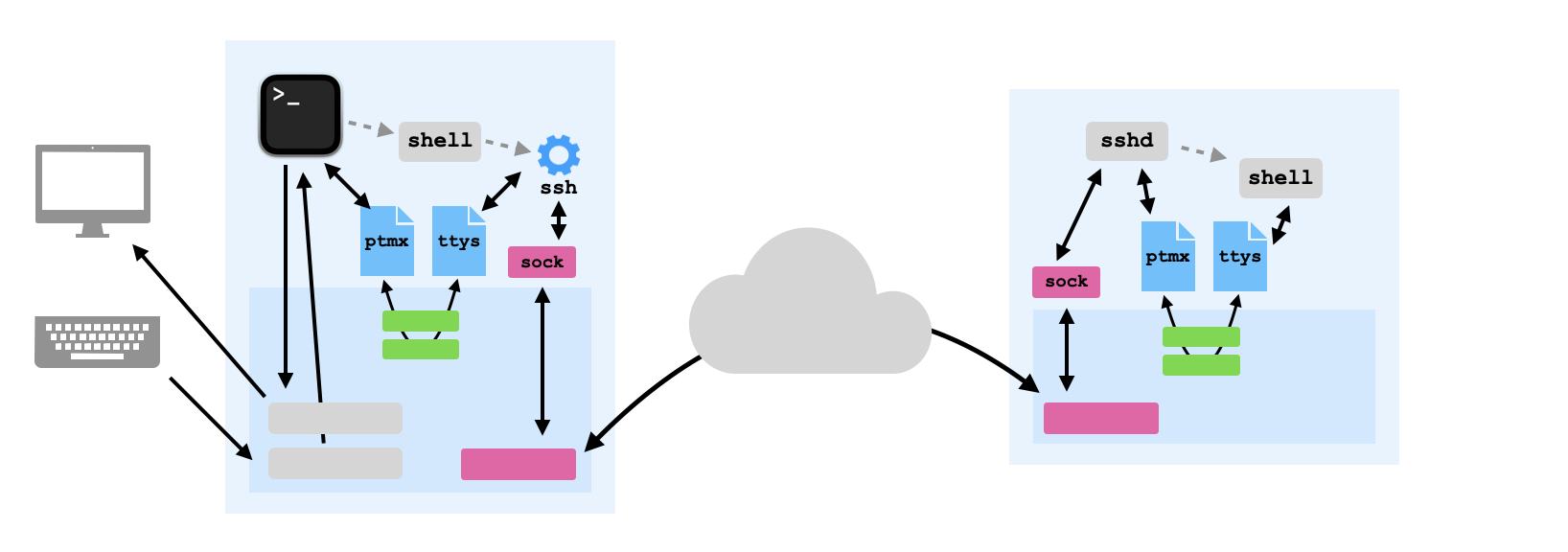
But hey, don't take my word for it. You can check a lot of this yourself using basic command-line utilities. Here's what I did to sanity-check my own understanding:
Terminal and use ssh to connect to a remote server.Terminal tab.ps -a | grep ssh to find the PID of the process running your SSH connection.lsof -p <pid> to see the list of open file descriptors for that process.stdin (file descriptor 0) is a TTY slave device. For my, stderr (file descriptor 2) was the same TTY slave, and stdout (file descriptor 1) was set to /dev/null.Terminal window with your remote SSH shell.pstree -p | grep sshd. You should see at least one sshd process with a shell as its child process. Grab both of their PIDs.lsof -p <sshd-pid>. (You may need sudo.) You should see /dev/ptmx among its open files.lsof -p <shell-pid>. You should see a TTY slave device open for all three of stdin, stdout and stderr.
(PTY master to PTY slave.) You might think that character data written to the master device can be read out from the slave device straightaway, like a pipe. But that's not quite right. The TTY subsystem offers a multitude of configurable settings regulating how characters are delivered to the slave end and mapping certain characters onto special actions. These settings are configurable through an API accessible to the child process.
Tell me about the line buffer
Among the configuration options provided by the TTY subsystem is the line buffer. By default, character input from the TTY master end is entered into a buffer, which is flushed with each newline character
\n. This means that not only does the shell not execute any command until you enter a newline, but it can't even access your characters until you enter a newline.The
termiosAPI allows a program to put its TTY device in "raw mode", which disables the line buffer and makes input available one character at a time. You can read more about it here. Note that shells often have their TTYs set to raw mode because a custom line buffer is the kind of convenience feature that would fall under a shell's purview. For instance, this allows shells to do things like allow you to browse your command history with the up- and down-arrow keys, which would not immediately be delivered to the shell in "cooked" mode.
Tell me why I can see my characters right away even when lines are buffered
The TTY mode is "cooked" rather than raw by default. So, for example, if you write a simple C program that reads input character by character from
stdin, and launch it from a shell, due to line buffering it will not receive any characters until the first newline is entered. However, you will still see the characters you type appear in your terminal as you type them.This has to do with another option offered by the TTY system: input echoing. With echoing turned on (which is the case by default), any characters written to the master TTY will also appear in the master TTY output, not just the slave TTY output. Hence, the terminal emulator reads back the same characters it had just written to the master TTY file, as if the slave process had printed those characters to
stdout- even though the slave may not have received those characters at all yet.
(PTY slave to char.) This can go either to the shell itself, or to a process that has been spawned from the shell. When you launch a process from a shell, it inherits the shell's stdin, stdout and stderr file descriptors. The shell and its child process both have the PTY slave device open while the child process is running, but the shell (normally) just waits for its child to finish and doesn't read from the PTY slave concurrently. Either way, chars are read from the PTY slave file using the read system call, as with any other file.
Tell me what happens when multiple processes read from the PTY slave concurrently
What happens is a race condition! Just like when multiple processes try reading from the same end of a pipe concurrently, some bytes may be read by one process while others are read by the other process. As for which bytes go to which process, it's not deterministic.
Try it out for yourself:
Terminal window.tty to see the TTY slave device name.Terminal window.cat /dev/ttysXXX, using the name from part (2).
(Char to PTY slave.) What the process does with the characters it receives simply depends on what kind of process it is. If it is a shell, it probably checks if the line entered is one of a few different built-in shell commands (of the flavor of cd or clear) or a binary executable found from some directory in the system PATH variable. If it is another process, it could do any number of things with its character input.
Whichever process is reading from the slave PTY, let us suppose that it produces some text output. As mentioned earlier, when the shell spawns a child process, its stdin, stdout and stderr file descriptors all point to the open PTY slave device by default. So unless the child process' output is being redirected to a file or piped to yet another process, it will be written right back to the PTY slave device.
Tell me how fancy CLIs like
vim or tmux completely change the appearance of my terminal
Just as the terminal emulator uses ANSI escape codes to transmit special characters to the child process reading from the TTY slave, that child can also use ANSI escape codes to send messages back to the terminal emulator. Many of the ANSI escape codes correspond not to special characters, but to actions that configure and manipulate the terminal's appearance.
These include special control sequences for moving the terminal cursor to the beginning or end of a line or even to a certan row and column position $(m,n)$ in the terminal's fixed-width text grid. There are also control sequences for changing the text color and background color of characters displayed in the terminal, and for hiding or showing the cursor in the terminal. A lot of these codes are documented in the VT220 Programmer Reference Manual which is chock-full of interesting little tidbits.
One of my favorites is the infamous "bell character": running
echo '\a'in a shell from your terminal emulator of choice will probably cause it to make a "boop" sound. When you run this, a process runningechowrites the bell character\a(which is0x07in ASCII) to the TTY slave device, the terminal emulator reads this character from the TTY master device, and produces a sound effect.If you're curious about the control characters that your favorite CLI program uses, the
teecommand can help you investigate by duplicating all of that program's raw output to a text file. For instance, if you want to investigate the control code used to drawvim's slick text-based UI, try runningvim hello.txt | tee dump.txt. Proceed to write some stuff in the filehello.txtand quit, and then open updump.txt(preferably in a hex viewer likexxd). You should see every character that appeared on the screen whilevimwas open, including graphical characters used to draw the UI, and a bunch of control sequences.
(PTY slave to PTY master.) Any characters written to the PTY slave device get shuttled back to the PTY master end, where the process that opened /dev/ptmx in the first place (the terminal emulator) can read them from its file descriptor. Note that although there may be other open file descriptors for /dev/ptmx, each one can only read characters written to the specific PTY slave that was created as a result of its opening. This is a big difference between PTY devices and pipes: many different processes may have the same file /dev/ptmx opened but read completely different character streams from it. That is to say: the OS discriminates between the different open file descriptors for /dev/ptmx, even though they correspond to the same open file.
(PTY master to glyph.) Finally, the terminal emulator reads characters from the TTY master and, when they are not part of a control sequence, displays them on the emulated terminal screen. It uses the fonts that are present on your system to decide how to draw each character. (You can find out exactly which font files your terminal emulator has open by finding out the PID of its running process and using lsof -p | grep Font.) On MacOS, these are usually .ttf or TrueType files. TrueType is a complicated beast, but in essence it provides for each glyph to be described as a sequence of Bezier Curves.
As for how the glyphs are displayed in a Terminal window, how the MacOS WindowServer manages the different overlapping application windows on your desktop, and how all of this graphical information is aggregated and mapped onto the pixels of your computer screen - that's a story for another day. It doesn't have enough to do with characters inherently to be on-topic for this post.
Cheers!

