En esta entrada pretendo exponer en breve un programa sencillo que he escrito en C para rastrear flujos de tráfico y guardar datos sobre ellos. El código se encuentra en un repositorio público en GitHub, así que puedes tranquilamente echar un ojo al código fuente si te interesa. Desde mediados del verano pasado, he participado en un proyecto de investigación que se trata de diseñar un sistema detector de intrusiones basado en el análisis de estadísticas asociadas a flujos de red. Aunque quedamos por ahora en la etapa de planificación y todavía no hemos empezado a escribir código concreto, yo me he dedicado a este proyecto pequeño aparte para familiarizarme con las herramientas en C que se usan para tramitar paquetes de red, en concreto la biblioteca libpcap.
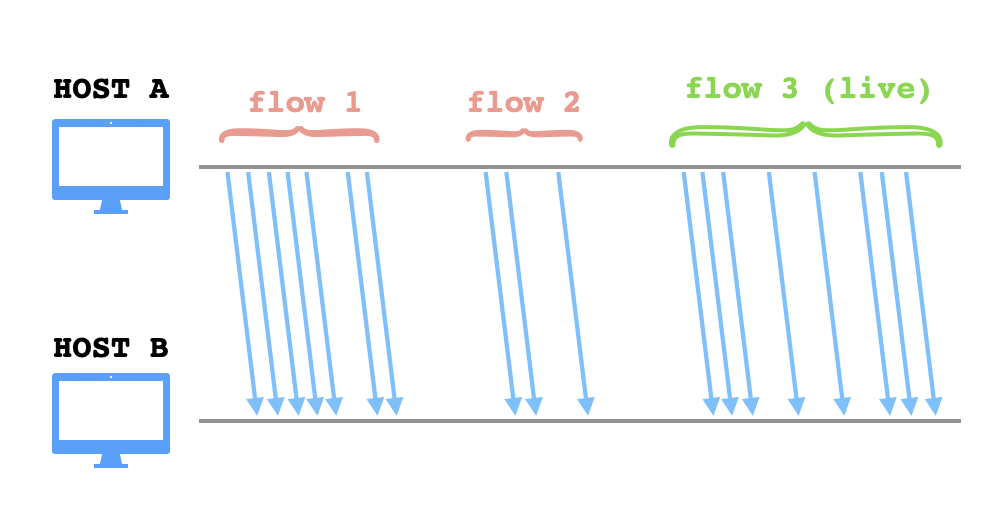
Un flujo es un agrupamiento de paquetes transmitidos por la red con el mismo origen, el mismo destino, correspondientes al mismo protocolo de transporte (TCP o UDP) y los mismos puertos de origen y destino. Se puede interpretar un flujo como una ráfaga de transmisiones relacionadas entre sí. En principio, no hay manera segura de determinar cuales paquetes transmitidos entre dos hosts distintos corresponden a la misma "transacción", pero se puede intentar adivinar un agrupamiento apto eligiendo un umbral para el retardo máximo entre paquetes del mismo flujo. Es decir, si el último paquete perteneciente a un flujo ha sido observado hace menos tiempo que el umbral fijo, entonces decimos que ese flujo está vivo, pero si ya más tiempo que el umbral ha pasado desde el último paquete, entonces decimos que está muerto, y cualquier paquete adicional que observemos a continuación (entre los mismos hosts, con el mismo protocolo y los mismos puertos) se clasificará como parte de un flujo distinto.
En mi código he definido cuatro estructuras que sirven para facilitar el rastreo de distintos flujos en progreso. Se llaman:
flow_id, estructura que contiene los datos necesarios para identificar un flujo unívocamente. En concreto: el momento de inicio y el momento de llegada del paquete más reciente, las direcciones IP de origen y destino, el protocolo y los puertos de origen y destino.flow_data, estructura que contiene todos los demás datos correspondientes a un flujo que no sirven para identificarlo.flow_node, estructura que sirve como nodo de una lista enlazada de flujos. Consta de datos de identificación, datos adicionales y un puntero a otro flow_node.flow_manager, estructura que contiene los componentes necesarios para una sesión de rastreo de flujos. Lleva dentro un parámetro que controla el umbral que se usa para delimitar flujos distintos a través del tiempo (además de otros parámetros de ajuste que podría agregar en el futuro) y dos listas enlazadas, siendo el primero el que lleva flujos vivos y el segundo el que lleva flujos muertos.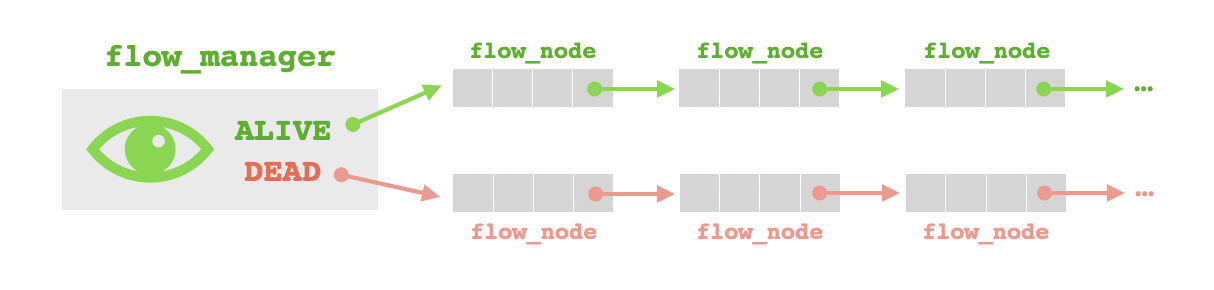
He escrito varias rutinas que llevan a cabo manipulaciones en las listas almacenadas por un gestor de flujo. Por ejemplo, una de ellas busca en la lista de flujos vivos del gestor un flujo con cierta identificación y lo crea si no existe. Otra rutina quita un flujo de la lista de vivos y lo mete en la lista de muertos. Pero hay una dificultad en la implementación de este rastreador de flujos: para mantener una lista de flujos vivos y otro de muertos, hay que poder quitar un flujo vivo de la lista de vivos en el mismo instante en el que caduca. ¿Cómo disparar el cambio de lista de cada flujo justo en el instante en el que él caduca, evitando problemas de sincronización y condiciones de carrera?
La verdad es que no hace falta preocuparnos con la sincronización. A propósito, en mi implementación, sólo se detecta los flujos muertos perezosamente, es decir, un nodo de flujo no se traslada a la lista de flujos muertos en el instante de caducidad, sino en el instante de estar "descubierto" cuando estamos buscando flujo vivo con los mismos datos de identificación y encontramos que éste, aunque tiene la identificación correcta, ya ha caducado. Así evitamos condiciones de carrera que serían muy difíciles de controlar en el caso de quitar flujos muertos de manera acaparador, a costo de un poco de eficiencia (pues mientras más flujos muertos acumulan en la lista de vivos, más nodos superfluos tendremos que recorrer al buscar un flujo). Por ahora estoy utilizando una lista enlazada sencilla con búsqueda secuencial para almacenar los flujos activos - claramente no es una solución muy expansible, pero he diseñado mi código de manera modular para facilitar la sustitución de estructuras de datos más optimizados en el futuro, por ejemplo una tabla hash.
En cuanto a la captura de paquetes en la red local, uso una biblioteca que se llama libpcap. Por defecto, una interfaz de red, como por ejemplo en0 en mi portátil, descarta todas las tramas que no sean destinadas por su misma dirección MAC, una dirección única de $6$ octetos que le corresponde a cada dispositivo hardware de red. Pero no es así por necesidad, y se puede igualmente abrir una interfaz de red en el modo promiscuo para que capte todas las tramas detectadas por la interfaz sin descartar las que no le corresponden. Aunque a primera vista podría parecer peligroso el hecho de que todos los otros dispositivos en nuestra subred puedan captar todo nuestro tráfico, la verdad es que toda información delicada debe ser cifrada de todos modos, y en muchos casos no se podrá captar el tráfico de otros hosts debido a la topología de conmutación en la red local. El tercer argumento a la función pcap_open_live (cuya documentación se encuentra aquí) permite abrir una interfaz en modo promiscuo, aunque podrían hacer falta permisos de administrador en el dispositivo para que el sistema operativo lo permita. En una red cableada con conmutadores (switches), las tramas ajenas que una interfaz podrá interceptar dependerá de la estructura conmutada de la red. Por ejemplo, considera la red conmutada siguiente:
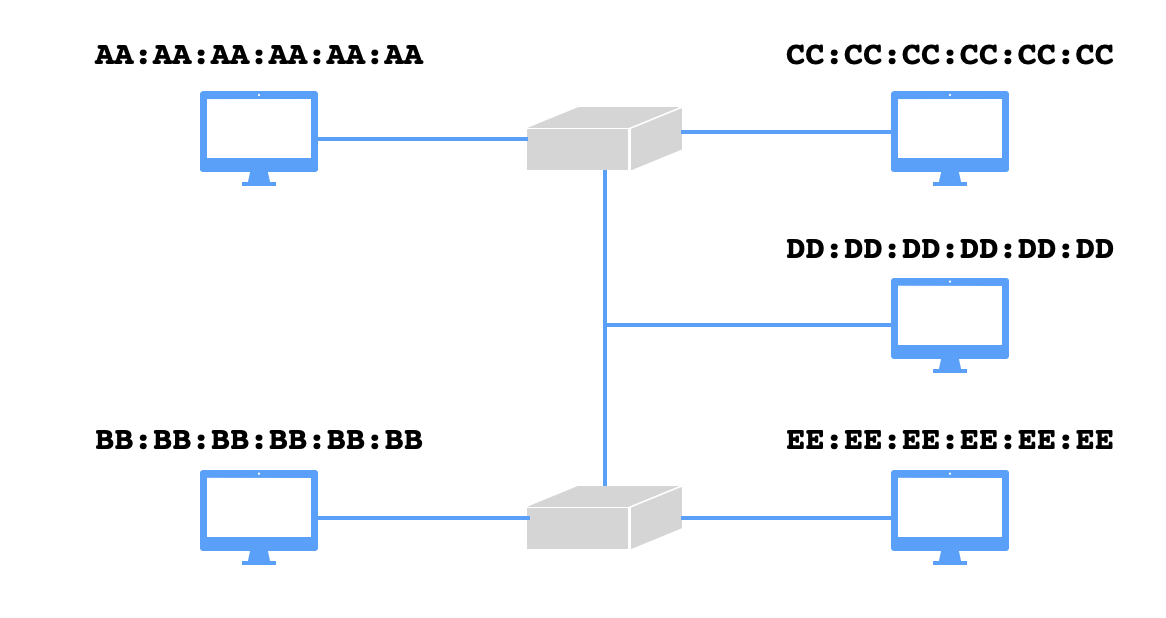
Una vez que los conmutadores aprenden las rutas de los $5$ hosts, no será posible que, por ejemplo, el host con MAC AA:AA:AA:AA:AA:AA intercepte una trama emitida por el CC:CC:CC:CC:CC:CC y destinada por el DD:DD:DD:DD:DD:DD, pues no queda en la ruta entre esos dos hosts. Por otro lado, el host DD:DD:DD:DD:DD:DD sí podría interceptar tramas con origen BB:BB:BB:BB:BB:BB y destino CC:CC:CC:CC:CC:CC. En una red inalámbrica con un punto de acceso central, no se podrá interceptar tramas ajenas salvo captando las señales radio crudas, y aún en ese caso se suele utilizar algún tipo de cifrado en las redes públicas entre el punto de acceso y cada host para proteger la privacidad de los usuarios. Así que, para captar información sobre las actividades de varios usuarios en una red, o tiene que ser una red bastante mal administrada, o tienes que tener dispositivo interceptor situado en una posición apropiada (por ejemplo, detrás del punto de acceso en una red inalámbrica).
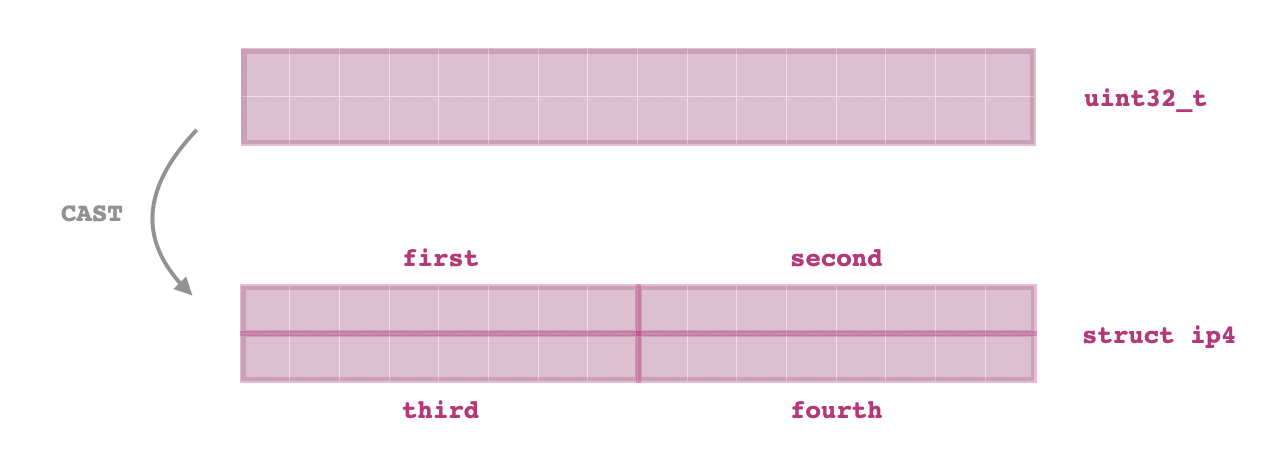
Una vez interceptada una trama, podremos acceder a sus bits crudos. En C hay un truco muy listo y conveniente que facilita tramitar las cabeceras anidadas de enlace, de red y de transporte mediante el casting de punteros a structs. Como los distintos campos de un struct están almacenados de manera serial en la memoria, si el largo de un struct es menor o igual al largo de otro, se puede esforzar que se interprete una instancia del segundo como instancia del primer sin problemas mediante el casting de punteros. Por ejemplo, si (en un sistema little-endian) tengo almacenado en un variable de tipo uint32_t una dirección IP de $32$ bits y quiero representarlo en el formato alternativo descrito por el struct siguiente:
struct ip4 {
uint8_t first;
uint8_t second;
uint8_t third;
uint8_t fourth;
};
Basta con realizar un simple casting de un puntero a nuestro variable de tipo uint32_t a un puntero de tipo struct ip4*. Tengo subido a GitHub un gist sencillo que demuestra esta técnica.
Podemos aprovechar la misma técnica con los bits crudos que obtenemos captando tramas. Se describe esta misma técnica en un tutorial del sitio web de libpcap. Se puede usar la función pcap_loop de la biblioteca para asignar una función callback a la que se le pasará un puntero a los bits crudos captados cada vez que está interceptada una trama. En el tutorial, definen una estructura que capta la estructura de una cabecera de ethernet:
/* Ethernet addresses are 6 bytes */
#define ETHER_ADDR_LEN 6
/* Ethernet header */
struct sniff_ethernet {
u_char ether_dhost[ETHER_ADDR_LEN]; /* Destination host address */
u_char ether_shost[ETHER_ADDR_LEN]; /* Source host address */
u_short ether_type; /* IP? ARP? RARP? etc */
};
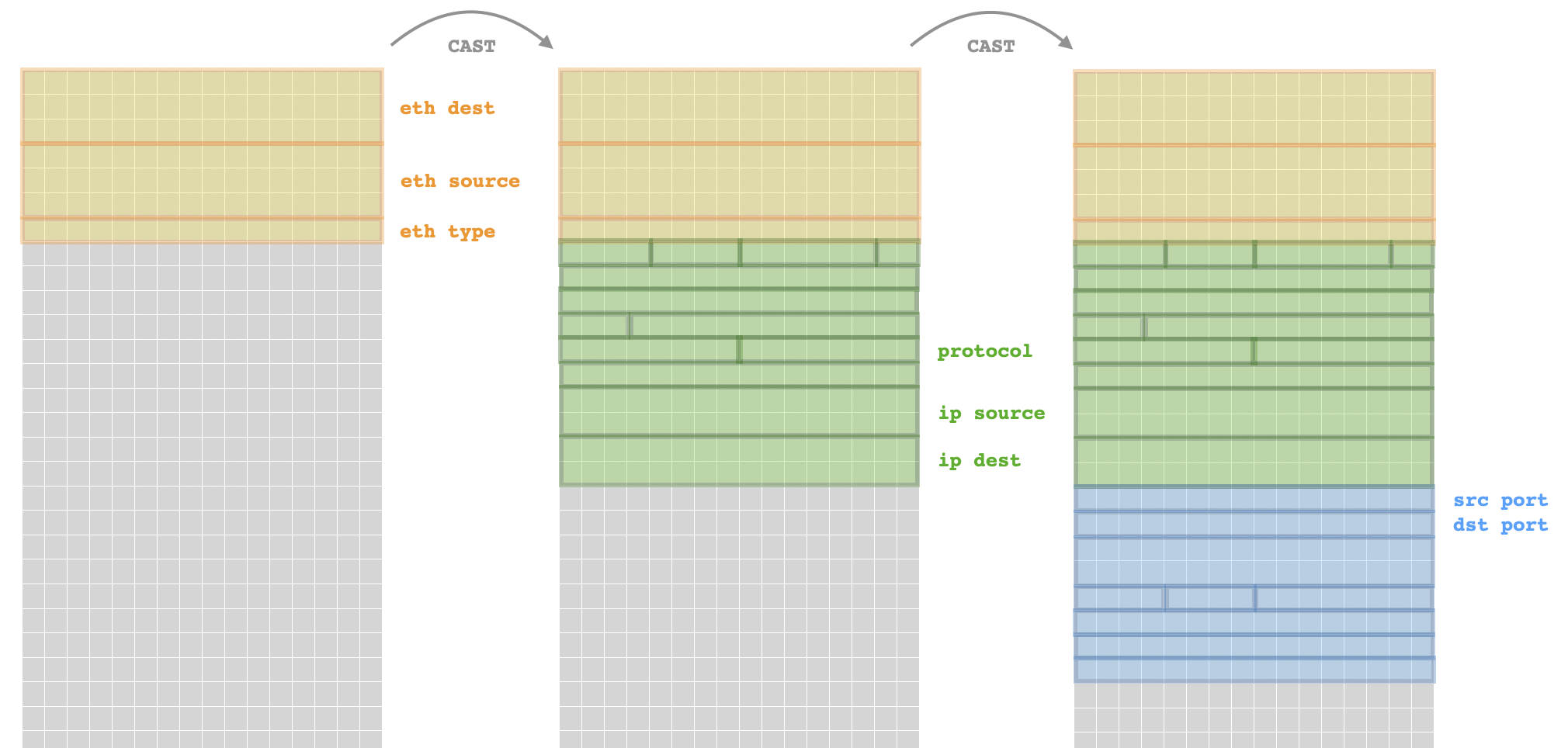
Entonces, para facilitar el acceso a los distintos campos de la cabecera de ethernet de una trama, se puede realizar un casting de un puntero a ella en memoria a un puntero de tipo struct sniff_ethernet*. Entonces se podrá acceder fácilmente a los campos de destino, origen y ethertype con el operador flecha que proporciona C. El tutorial también proporciona estructuras para la cabecera IP y la cabecera TCP. Como la cabecera UDP es bastante sencilla, he escrito por mi cuenta una estructura que se puede usar para tramitarla:
struct sniff_udp {
u_short uh_sport;
u_short uh_dport;
u_short uh_len;
u_short uh_sum;
};
Llevando a cabo una sucesión de castings se puede extraer una cabecera ethernet formateada, una cabecera IP formateada y una cabecera TCP (o bien UDP) formateada.
Después de ejecutar el rastreador de flujos en mi portátil por varios minutos y detenerlo, obtengo una lista de los flujos captados:
srcip,dstip,prot,srcport,dstport,count,bytes,dur
17.36.203.0,10.88.166.9,TCP,443,64792,1,4668543963722940416,0.000092
10.88.253.121,255.255.255.255,UDP,56216,1947,1,4670514288559915008,0.000092
10.88.253.121,10.88.255.255,UDP,56215,1947,1,4670514288559915008,0.000093
10.88.166.9,17.36.203.0,TCP,64792,443,1,4670232813583204352,0.000102
...

